題記の通りで、OCRを使えると便利だなとか思ったりして調べてみた。
そもそもの発端はUbuntuのドキュメントスキャナーにちょっとした不満があったのがきっかけ。
せっかくCannon MG3630っていうそこそこなプリンタ&スキャナーを持っているのに、B5サイズでのスキャンができない。(A3〜A6とレターしかできないので余白ができる。まあ後で余白だけ消せばいいんだけど。)
で、他のスキャナーを探してたらアプリケーションセンターにgImageReaderというのがある。こいつはスキャナー兼OCRらしいのでこりゃ便利と思ってインストール。しかしいっぱいエラーが出る。
そんなわけでお勉強したのでした。
gImage Readerはスキャナ+OCRのフロントエンド
gImage ReaderはスキャナなんだけどOCRの機能も持ってる。と思ったら大間違い。OCRの部分はただのフロントエンド。
OCR自体はTesseract-OCR(テセラクト)というソフトが必要。
しかもTesseract-OCRはそのまんまでは日本語を読めないので日本語の認識データを追加してあげる必要がある。
Tesseract-OCRをインストールする
$ sudo apt update $ apt search tesseract tesseract-ocr/groovy 4.1.1-2build3 amd64 ←tesseract本体 tesseract-ocr-all/groovy,groovy 4.1.1-2build3 all ←全言語の認識データ tesseract-ocr-eng/groovy,groovy 1:4.00~git30-7274cfa-1 all ←英語 tesseract-ocr-jpn/groovy,groovy 1:4.00~git30-7274cfa-1 all ←日本語 tesseract-ocr-jpn-vert/groovy,groovy,now 1:4.00~git30-7274cfa-1 all←日本語(縦書き) :
いろいろなにかが表示されるが、要するに teserract-ocr(本体)と使いたい言語をインストールすれば良い様だ。
tessecact-ocr-allをインストールすると全言語がインストールされるが/usr/shareを700MBくらい食いつぶすのでやめた。英語と日本語だけインストールする。
あと、文脈を解釈tesseract-ocr-script-jpan/jpan-vertも入れておく。
$ sudo apt install tesseract-ocr tesseract-ocr-eng tesseract-ocr-jpn tesseract-ocr-jpn-vert tesseract-ocr-script-jpan tesseract-ocr-script-jpan-vert $ ls -1 /usr/share/tesseract-ocr/4.00/tessdata/*trained* /usr/share/tesseract-ocr/4.00/tessdata/Japanese.traineddata /usr/share/tesseract-ocr/4.00/tessdata/Japanese_vert.traineddata /usr/share/tesseract-ocr/4.00/tessdata/eng.traineddata /usr/share/tesseract-ocr/4.00/tessdata/jpn.traineddata /usr/share/tesseract-ocr/4.00/tessdata/jpn_vert.traineddata /usr/share/tesseract-ocr/4.00/tessdata/osd.traineddata
試しにOCR機能を使ってみよう。
適当なフォルダにこの様なJPG or PNGファイルを保存する

同じフォルダでtesseractコマンドを実行する。
usage : tesseract imagefile outfile [ -l language ]
tesseractコマンドフォーマット
imagefile : 画像ファイル名
outfile : 出力ファイル名 .txtは勝手についてくれる
language : 日本語の場合はjpnを指定。何もしないと英語になる
ex) tesseract test.jpg text1 -l jpn
→ 日本語で解釈した結果がtext1.txtに出力される
$ tesseract test.jpg test1 $ cat test1.txt TEST TAk aN aR $ tesseract test.jpg test2 -l jpn $ cat test2.txt TEST テスト 試験
上記の通り、 -l jpnを付ければ日本語を正しく解釈できる。
さあ、これでgImate Readerを使える。と思ったら大間違い。
Hunspellをインストール
gImage ReaderはHunspellを使っている。
HunpellというのはGoogleが使っているスペルチェッカーで、LibreOfficeなんかも使用している。
gImage ReaderはHunspellがないといっぱいエラーを履くのでインストールしてあげる必要がある。あと、日本語の辞書(.dic)もインストールしてあげないとOCRが機能しない。
ただ、Hunspellは日本語の辞書が無いことが判明(笑)
とりあえずHunspell自体はインストールする。
$ apt search hunspell | grep "/" hunspell/groovy,now 1.7.0-3 amd64 ←本体 (残念なことにhunspell-jaは見つからない) : $ sudo apt install hunspell $ ls /usr/share/hunspell en_AU.aff en_AU.dic en_CA.aff en_CA.dic en_GB.aff en_GB.dic en_US.aff en_US.dic en_ZA.aff en_ZA.dic
とっても残念。でも仕方ない。
gImage Readerをインストール
やっとここまで来ました。ソフトウェアセンターでインストールして起動してみましょう。
gImage ReaderでOCRを使ってみる
とりあえずgImage Readerを起動してみる
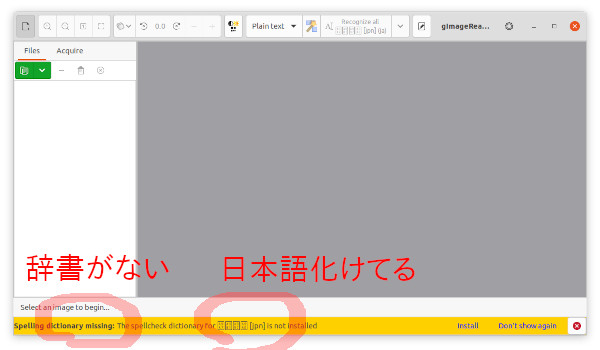
まあ予想通り辞書がないというエラーがでますね。
ついでに日本語[jpn]と表示されるべき部分が化けてる(笑)
このメッセージがうっとおしい場合は右上の設定マーク(ギアのやつ)からPreferences > Query to install missing spell check dictionaries のチェックを外すせば次回から表示されなくなります。
気にせずOCRで読み取ってみる
先程保存したtest.jpgを読み込んでみましょう。
まず、Filesでファイルを読み込んで、読み込む言語を選択します。
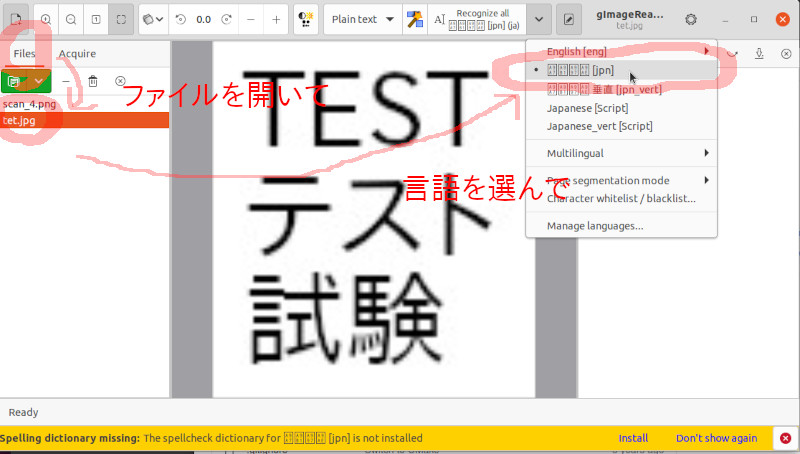
読み込む範囲を選択して、言語をクリック。すると右に読み込んだテキストが出る。
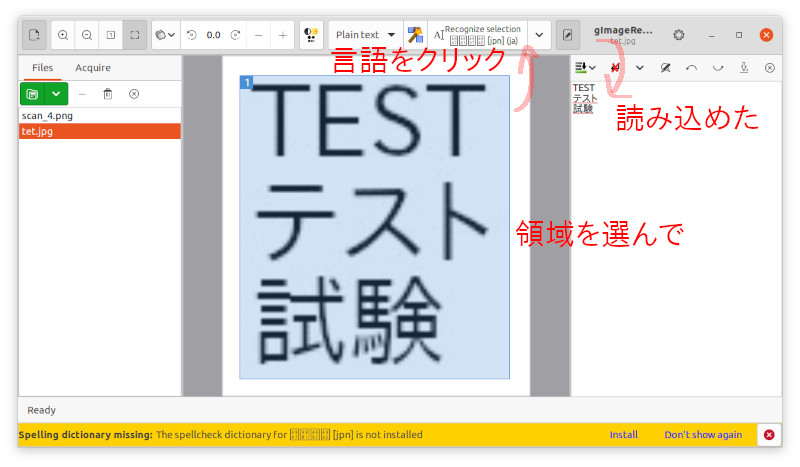
なかなかの精度に見えますね。
でもこれ、文字が大きいからなんです。
例えばスキャナで読み込む際に75dpiにすると、小さい文字は全く読めなかったり。フォントが背景ににていたりすると格段に精度が落ちます。
6ptのフォントで書かれた契約書を200dpiで読み込んだら99.95%正確に読み込めました。1文字だけ謎の">"という文字が入っていただけです。
白黒横書きのテキストを読み込むだけならtesseractコマンドを使えば何十枚もあるテキストを一気に読み込めて便利。
GUIを使って特定の領域だけ読み込みたいならgImage Readerを使う感じですね。
あ、大事なこと忘れてた。
gImage ReaderではスキャナのサイズはA4固定です。なのでB5で読みたいという目的は達成できませんでした。(笑)